
E4b9a6's blog
有善始者实繁,能克终者盖寡。
作者:E4b9a6, 创建:2023-07-18, 字数:38317, 已阅:1991, 最后更新:2024-06-14
这篇文章更新于 315 天前,文中部分信息可能失效,请自行甄别无效内容。
本文是针对 Python 开发的一些内容,是在实际工作与实践中积攒的一些常见基础以及知识点
互联网上的 Python 中文资料已经非常详细了,所以本文更关注实际用途,更合适有基础的开发人员快速阅览
以下所涉及到的库与语法都在 Python3.7.2 实践,请自行甄别不同版本之间的差异
Python的开发环境搭建非常简单,在 Python官网 中根据需要下载对应系统架构安装
下载安装包,双击安装包,记得勾选 添加到PATH 选项,然后点击立即安装
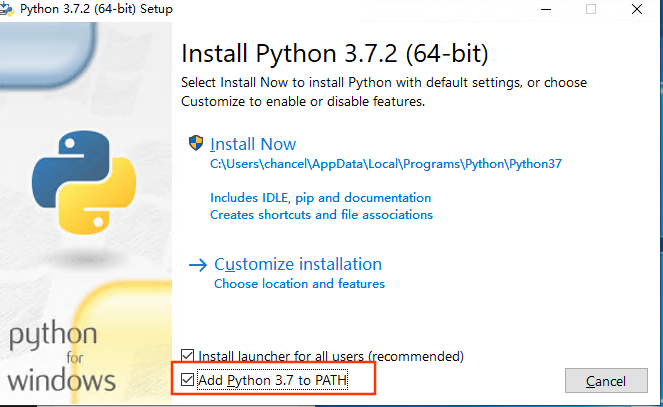
部分发行版可以直接通过库管理安装,这里以编译安装为例
安装编译工具
Debian10
sudo apt update
sudo apt install libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev zlib1g-dev make gcc
Cent7 OS
sudo yum update
sudo yum -y install wget xz tar gcc make tk-devel sqlite-devel zlib-devel readline-devel openssl-devel curl-devel tk-devel gdbm-devel xz-devel bzip2-devel
Alpine
sudo apk update
sudo apk add wget curl vim git build-base openssl-dev zlib-dev libffi-dev make automake gcc g++ subversion python3-dev
解压并编译安装到 /usr/local/python3.7.2 中
mkdir /tmp/python3.7.2 && cd /tmp/python3.7.2
wget https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tgz
tar -zxvf Python-3.7.2.tar.gz && cd Python-3.7.2
./configure --prefix=/usr/local/python3.7.2
sudo make
sudo make install
将安装路径添加到系统环境中 Path 中
sudo ln -s /usr/local/python3.7.2/bin/python3 /usr/bin/python3.7.2
将以上安装步骤写成一个 安装脚本 , 使用方法如下
bash install-py.sh --version=3.7.2 --path=/usr/local
Python的主要IDE有以下几个
Visual Studio Code 是微软家的轻量级IDE,对 Python 开发非常完善,但大部分初始化工作需要手动,适合有一定经验的开发人员
PyCharm 是 JetBrains 针对 Python 推出的收费IDE,算是 Python 的业界标杆,适合任何人,社区版免费
下面所有实践均基于 Visual Studio Code ,以下简称 VSC ,下载地址:
如下图是我常用的Python插件
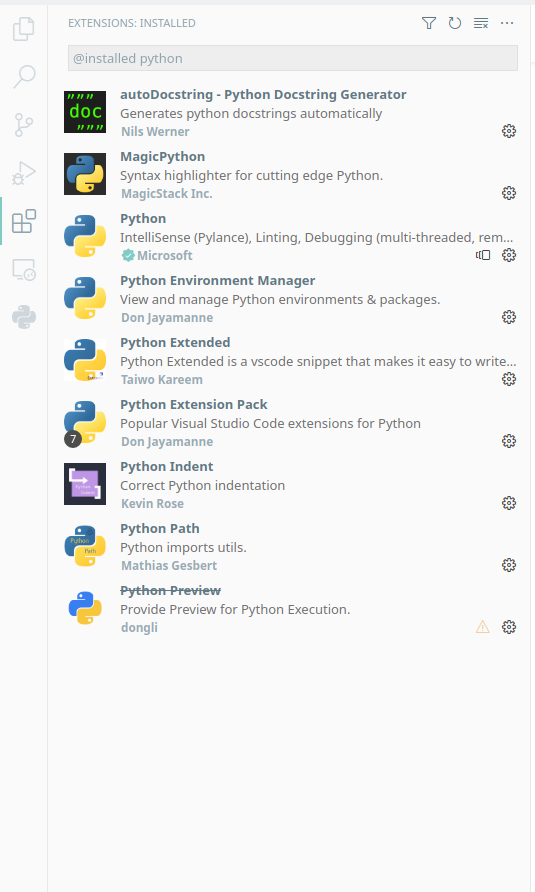
在插件安装完成后,重新运行VSC,创建一个文件夹并使用VSC打开该文件夹,建立一个 main.py 文件
内容如下,按F5运行
print("Hello World")
配置VSC环境后,按F5可启动当前文件DEBUG调试,类似于下面的效果
python3 main.py
项目通常会伴随着一些启动参数,如下列代码
import argparse
parser = argparse.ArgumentParser(description='Test for argparse')
parser.add_argument('--name', '-n', help='your name', default='chancel')
parser.add_argument('--age', '-a', help='your age', default=100)
args = parser.parse_args()
print('your name is %s, your age is %s' % (args.name, args.age))
在VSC中,在启动时带入参数,类似于下的效果
python3 main.py --name lisa --age 18
# 输出如下
your name is lisa, your age is 18
为上面这样的自定义参数启动创建 VSC 的项目配置,如下图
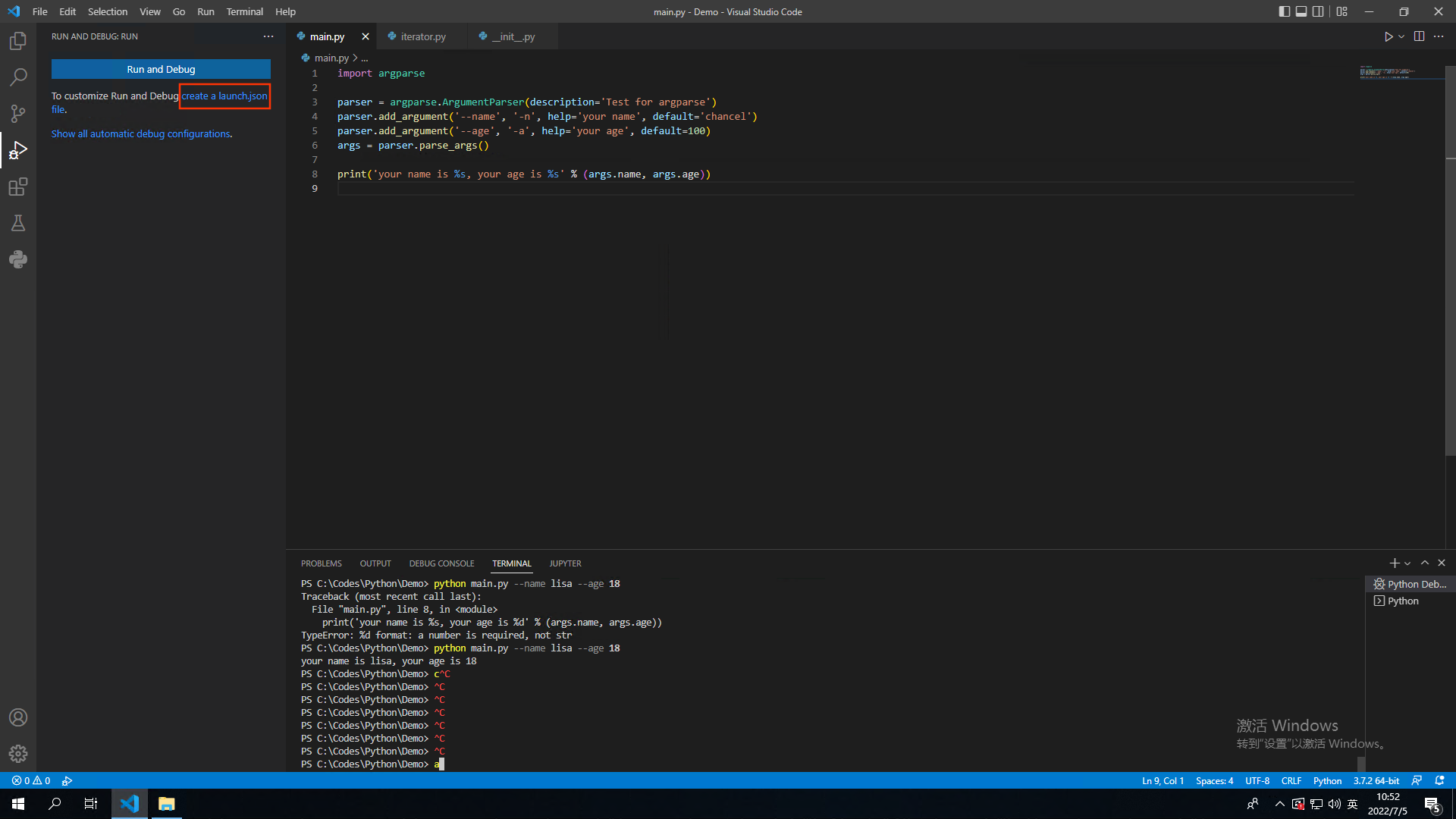
创建Python的配置文件类似如下
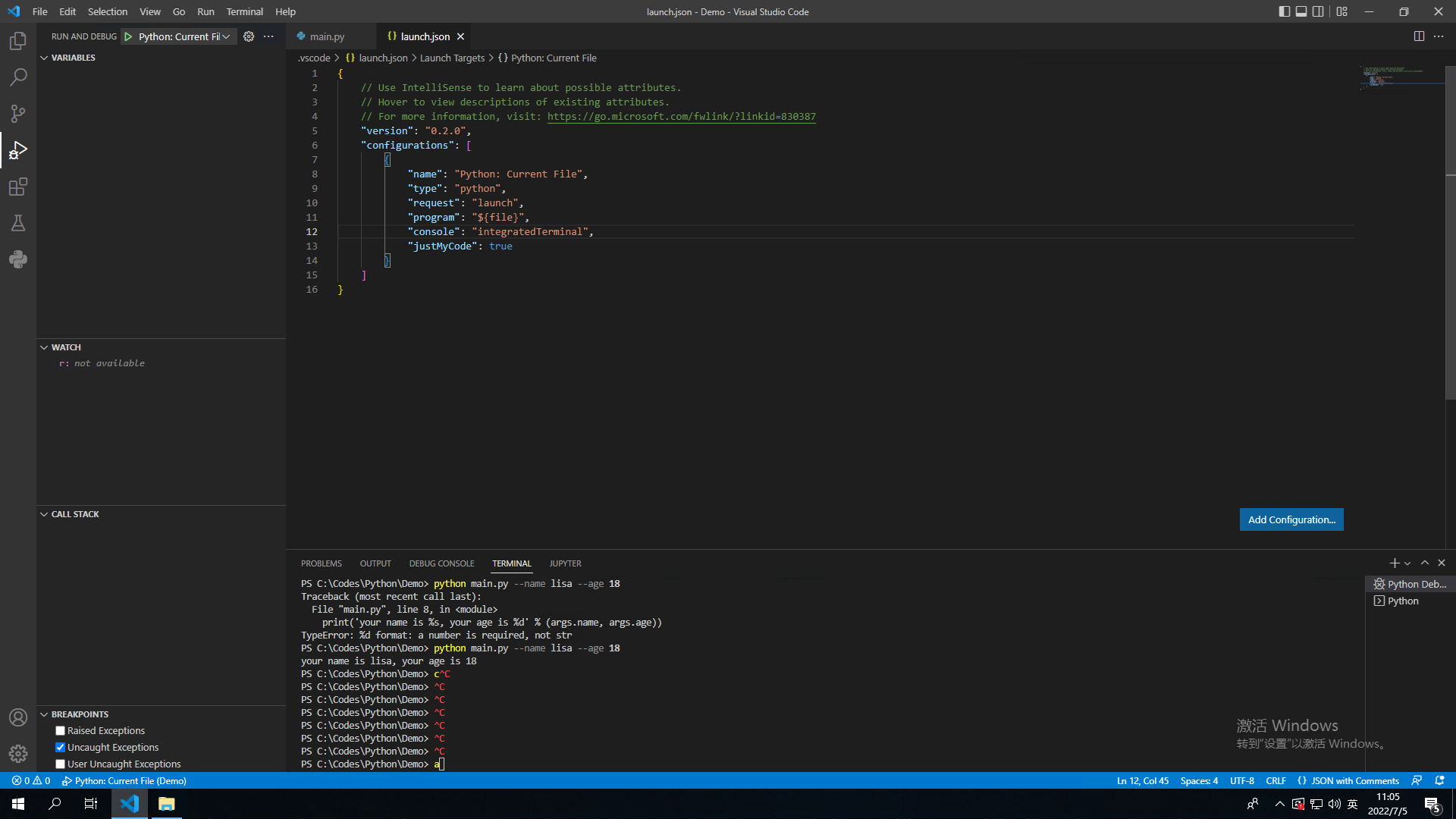
基于上面的代码,我们可以修改项目启动配置单如下
program 指定了程序入口,args指定了启动的配置参数
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${workspaceRoot}/main.py",
"console": "integratedTerminal",
"args": ["--name=lisa","--age=18"],
"justMyCode": true
}
]
}
下面是一份 Flask应用 的启动配置文件
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Flask",
"type": "python",
"request": "launch",
"module": "flask",
"host": "0.0.0.0",
"console": "internalConsole",
"python": "/home/chancel/codes/python/chancel-blog/.env/bin/python",
"env": {
"FLASK_APP": "${workspaceRoot}/src/flaskr",
"FLASK_ENV": "development",
"FLASK_DEBUG": "1",
"APP_CONF":"${workspaceRoot}/conf/app.conf"
},
"args": [
"run",
"--no-debugger",
"--no-reload",
"--host=127.0.0.1",
"--port=5000",
],
"jinja": true
}
]
}
Python的数据类型有 number, String, List, Dictionary, Tuple, Set 几种
数字类型包含整数、浮点数、负数,其中整数 0 等价于 False ,1 等价于 True ,数字类型可以作为运算符运算
user_age = 100
user_name = 'chancel'
user_type = ['admin','common']
user_info = {'gender':'male'}
基础类型与其他编程语言基本一致
保留字
Python 中保留字(语法关键字)不能用作任何标识符或变量名称,保留字列表可以从自带模块 keyword 中获取
import keyword
print(keyword.kwlist) # ['False', 'None', 'True', ..., 'yield']
mutable and immutable
Python中, string、number、tuple 均是不可变对象(immutable), list、dict、set则是可变对象(mutable)
immutable 和 mutable:
分清楚这两者在日常编程时有助于减少代码错误
mutable_str = 'hello'
immutable_dict = {'hello': 'world'}
def change_str(my_str: str):
my_str = my_str + my_str
def change_dict(my_dict: dict):
my_dict['new'] = 'object'
print('str:%s, dict:%s' % (mutable_str, immutable_dict)) # str:hello, dict:{'hello': 'world'}
change_str(mutable_str)
change_dict(immutable_dict)
print('str:%s, dict:%s' % (mutable_str, immutable_dict)) # str:hello, dict:{'hello': 'world', 'new': 'object'}
可以看到在函数传递时,string 的值不会被改变,而 dict 的值则被改变了
切片
Python 的切片语法非常适合处理数据,如对字符串做切割:
letters = 'abcdefghijklmnopqrst'
# 截取前7个字母
print(letters[0:7]) # abcdefg
# 截取后7个字母
print(letters[-7:]) # nopqrst
# 每2个元素取出一次
print(letters[0::2]) # acegikmoq
每一次切片会生成一个新的对象
切片支持几乎所有 Python 数据类型,包括 string, list, range, tuple, unicode 等
List
list 是 Python 中的数组
my_list = ['Love', 'you', 2008, True]
print('index 2 value is', my_list[2]) # index 2 value is 2008
my_list.append('Just')
print('append value is', my_list[-1]) # append value is Just
del my_list[0]
print('now index 2 value is', my_list[2]) # now index 2 value is True
List 数据类型灵活,声明无需限定长度,对对象内容没有限制,常用扩展方法包括:
Dict
Dict 是字典数据类型
Json 数据在 Python 中可以很轻松的转换为 Dict
Key值类型通常为String,也支持 number, tuple 等不可变数据类型
my_dict = {'name': 'chancel'}
my_dict['age'] = 300
print('%s age is %d' % (my_dict['name'], my_dict['age'])) # chancel age is 300
del my_dict['age']
my_dict['real_age'] = 10
print('%s age is %d' % (my_dict['name'], my_dict['real_age'])) # chancel age is 10
my_dict['gender'] = 'male'
for key, value in my_dict.items():
print('dict key %s, value is %s' % (key, value))
# dict key name, value is chancel
# dict key real_age, value is 10
# dict key gender, value is male
以下代码举例 Python 中的 if、while、for 的用法
# 空值
str_1 = None
# Bool值
bool_1 = True
# 数字类型
number_1 = 9
# 数组语法
list_1 = []
# 判断语法
if len(list_1) < 1:
print('list_1 is empty list') # list_1 is empty list
# 循环语法
for i in range(10):
list_1.append(i)
print('list_1 value is ', list_1) #list_1 value is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 关键字in
if number_1 in list_1:
print('number_1 contain in list_1') # number_1 contain in list_1
# 关键字not表相反
if not str_1:
print('str_1 is empty') # str_1 is empty
# and表示2个条件成真则为真
if bool_1 and not str_1:
print('bool_1 is True and str_1 is empty') # bool_1 is True and str_1 is empty
# or 表示2个条件其中1个为真的整体为真
if bool_1 or str_1:
print('bool_1 is True or str_1 is empty') # bool_1 is True or str_1 is empty
# continue表退出当前此次循环,brak表示退出整个循环
for i in range(10):
list_1.append(i)
if i == 3:
continue
if i == 5:
break
print('list_1 value is ', list_1) # list_1 value is [0, 1, 2, 3, 4, 5...]
while len(list_1) > 0:
print(list_1.pop()) # 5,4,3,2,1...
函数在 Python 中使用 def 进行定义,如下:
def get_name() -> str:
return 'chancel'
其中 -> 非强制要求,是函数返回值的注解,在入参方面Python与其他编程语言没有区别,可携带默参
比较特殊的是可采用关键字传参,而不是顺序传参,如下:
def area(height: int = 3, width: int = 4) -> int:
return height * width
print(area()) # 12
# 通过关键字传参,对参数顺序无要求
print(area(width=5, height=6)) # 30
Python 的函数支持可变参数的写法,其中 *args 和 **kwargs 代表可变参数和可变参数键值对,如下:
def args(*args, **kwargs):
for arg in args:
print(arg)
for key, value in kwargs.items():
print('key:%s, value:%s' % (key, value))
args('1', '2', '3', name='chancel', age=18)
# 1
# 2
# 3
# key:name, value:chancel
# key:age, value:18
args 和 kwargs 是约定俗成的名称,并非强制要求,区别位置参数和关键字参数的是 * 和 **
Python同样支持lambda表达式,如下:
double = lambda x: x * 2
print(double(18)) # 36
在 Python 中,异常是一种特殊事件,与其他编程语言是类似的
通常,当 Python 程序无法按照正常流程处理时就会抛出异常,如网络异常/文件被占用/端口被占用等情况
捕捉异常可以使用 try、except、finally ,示例代码如下
import os
file_name = os.path.join(r'C:\Windows', r'win.ini')
f = open(file_name, 'r')
try:
f.write('s')
except Exception as e:
print(e) # not writable
finally:
f.close()
print('file close') # file close
BaseException 是Python中所有异常的基类,需要自定义异常要继承这个基类
except 后可以接多个异常类型来代表捕捉多个可能的异常,以方便处理对应的异常
下面使用raise来抛出自定义错误
class NotStrError(Exception):
def __init__(self, *args: object) -> None:
super().__init__(*args)
try:
a = 100
if type(a) != str:
raise NotStrError("value is not string")
except NotStrError as e:
print(e) # value is not string
Python 的标准库是 Python 的最大特色之一
官方对于标准库的详细文档:
下面会介绍一些在开发中比较常用的标准库
os 库是日常最常用的库之一,用于与操作系统进行交互,包括处理环境变量、获取系统资源、请求系统API等
os.path 是 os 库中用于和文件系统交互的模块,如下:
import os
file_name = os.path.join(r'C:\Windows', r'win.ini')
with open(file_name, 'r') as f:
print(f.readline()) # ; for 16-bit app support
os.path包括如下方法:
文档参考:https://docs.python.org/zh-cn/3.7/library/os.path.html
sys 是 Python 中提供与解释器相关操作的标准库:
$1 $20代表正常退出,其他参数代表异常退出执行下面的代码
import sys
print(sys.argv[0])
print(sys.argv[1])
print('sys.path:%s' % sys.path)
print('sys.platform:%s' % sys.platform)
sys.exit(0)
输出如下
main.py
hello
sys.path:['/tmp/demo', ..., /usr/lib/python3.10/site-packages']
sys.platform:linux
shutil 是 Python 中用于对文件和文件系统进行操作的专用库(shell utilities)
以下面的例子说明shutil中几个常用方法copy、move、copytree、rmtree
import shutil
import os
dir_path = '/tmp/shutil'
new_dir_path = '/tmp/new_shutil'
os.mkdir(dir_path) # 创建测试文件夹
file_path = '/tmp/shutil/hi.txt'
new_file_path = '/tmp/shutil/new_hi.txt'
with open(file_path, 'w') as f:
f.write('hi') # 向文件写入字符串'hi'
shutil.copy(file_path, new_file_path) # 若目标文件已存在,复制会覆盖
try:
shutil.move(file_path, new_file_path) # 若目标文件已存在,移动会报错
except Exception as e:
print('move file error: %s' % str(e))
shutil.copytree(dir_path, new_dir_path) # 复制文件夹
shutil.rmtree(dir_path) # 删除文件夹
shutil.make_archive(dir_path, 'zip', new_dir_path) # 压缩文件夹成shutil.zip
shutil.rmtree(new_dir_path) # 删除文件夹/tmp/shutil
shutil.unpack_archive(dir_path + '.zip', new_dir_path) # 解压shutil.zip
json 是 Python 中用来处理 Json数据 标准库
import json
data = {
"name": "chancel",
"age": "100",
"interest": [
"badmintor",
"python"
],
'msg': '偷得浮生半日闲'
}
print(json.dumps(data))
# 若有中文,则需要指定ensure_ascii参数为False,否则将以ascii编码输出中文导致乱码
print(json.dumps(data, ensure_ascii=False))
with open('/tmp/json.json', 'w') as f:
f.write(json.dumps(data))
# load与loads的区别在于前者接收json文件流,后者接收json字符串
with open('/tmp/json.json', 'r') as f:
print(json.load(f))
with open('/tmp/json.json', 'r') as f:
print(json.loads(f.read()))
输出如下
{"name": "chancel", "age": "100", "interest": ["badmintor", "python"], "msg": "\u5077\u5f97\u6d6e\u751f\u534a\u65e5\u95f2"}
{"name": "chancel", "age": "100", "interest": ["badmintor", "python"], "msg": "偷得浮生半日闲"}
{'name': 'chancel', 'age': '100', 'interest': ['badmintor', 'python'], 'msg': '偷得浮生半日闲'}
{'name': 'chancel', 'age': '100', 'interest': ['badmintor', 'python'], 'msg': '偷得浮生半日闲'}
time 和 datetime 是 Python 处理日期与时间处理的标准库
import datetime
import time
# 9位的时间戳 - 1658387394.2734408
print(time.time())
# 13位的时间戳 - 1658387394273
print(int(round(time.time()*1000))) #
# time.struct_time(tm_year=2022, tm_mon=7, tm_mday=21, tm_hour=15, tm_min=9, tm_sec=54, tm_wday=3, tm_yday=202, tm_isdst=0)
print(time.localtime())
# 2022-07-21 15:09:54
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
# 2022-07-21 15:09:54.273676
print(datetime.datetime.today())
# 2022-07-21 15:09:54.273741
print(datetime.datetime.now())
# 2022-07-21 15:09:54.273764
print(datetime.datetime.fromtimestamp(time.time()))
# 2022-07-21 14:04:35
print(datetime.datetime.strptime('2022-07-21 14:04:35', '%Y-%m-%d %H:%M:%S'))
# 3
print(datetime.datetime.now().weekday())
module 是一个单独的 Python 文件,包含了一组相关的函数、类、变量和/或语句
.so、.pyo,.pyc,.dll都可以作为模块引入,都可以视为是一个单独的Python文件
编辑一个 user.py 文件
name = 'chancel'
_age = 100
def print_name():
print(name)
def get_age() -> int:
return _age
class User:
pass
if __name__ == '__main__':
print('i\'m free')
再在相同目录下,创建一个 main.py文件
import user
print(user.get_age()) # 100
user.print_name() # chancel
my_user = user.User()
print(type(my_user)) # <user.User object at 0x000002B0D0221BA8>
user.py 相当于一个 user module
如果单独执行user.py,则可以发现输出了“i'm free",这是因为
__name__变量值为main__name__变量值为文件名称借助这个特性,可以在模块中撰写测试代码而不影响其他引用者
Package 是一个包含多个模块的目录,通过特定的结构和init.py文件来组织模块
当import一个module时,Python解释器的引入顺序是:
在大型项目中,需要用到大量的module,这个时候通常会封装成package便于管理,导入package时,会隐式的执行 __init__.py 文件
用文件系统类比,将 module 看成文件,将 Package 看成目录
创建一个 models 文件夹,并将 user.py 移入其中,再创建一个空的 __init__.py 文件
此时项目结构如下
$ tree
.
├── main.py
└── models
├── __init__.py
└── user.py
1 directory, 3 files
在 main.py 中运行以下代码
from models.user import User
user = User()
print(user) # <models.user.User object at 0x0000027044B2A2B0>
修改 __init__.py 文件
from models.user import User
此时,在 main.py 中,可以改成这样引入 user
# from models.user import User # 旧的引用方式
from models import User
user = User()
print(user) # <models.user.User object at 0x0000027044B2A2B0>
在操作系统中,安装多个 Python 版本可以借助 Anaconda、miniconda、pyenv
以 pyenv 为例,在Debian11上管理多个Python版本
对于主流操作系统如Windows、MacOS、Debian、CentOS等pyenv都提供自动化安装脚本
curl -L https://raw.githubusercontent.com/yyuu/pyenv-installer/master/bin/pyenv-installer | bash
配置环境变量
cat << EOF >>~/.bashrc
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
EOF
pyenv 的常见使用如下
# 所有可安装的版本列表
pyenv install -list
# 下载制定版本的Python
pyenv install 3.7.2
# 查看当前已下载的版本
pyenv versions
# 设置系统的Python版本
pyenv global 3.7.2
# 设置当前目录为某个Python版本
pyenv local 3.7.2
# 更新pyenv
pyenv update
安装 pyenv 后,使用 pyenv 安装 3.7.2 版本,并设置当前文件夹的 Python 环境为Python3.7.2
pyenv install 3.7.2
pyenv local 3.7.2
以后只要进入了当前文件夹(demo)则默认会启用3.7.2的Python版本
➜ pwd
/home/chancel/codes
➜ python -V
Python 2.7.17
➜ cd /home/chancel/codes/demo
➜ python -V
Python 3.7.2
使用版本管理的好处:
许多编程语言都有虚拟环境,虚拟环境是一个独立的、隔离的 Python 环境,让多个 Python 项目的环境互相不干扰
例如有 项目A 和 项目B 都使用 Python3.7.2 的环境,一个依赖 requests > 2.27.1 ,一个依赖 requests > 1.71.1
虚拟环境可以隔离这两个环境从而实现针对不同项目安装相同库的不同版本
为某个目录启用 venv 环境方法如下
python -m venv myvenv
source myenv/bin/activate
激活虚拟环境后,在该环境中安装和使用特定版本的Python解释器和依赖库,而不会影响到主机系统或其他虚拟环境
查看项目的 myvenv 文件夹
(myenv) $ ll venv
total 16K
drwxrwxr-x 2 chancel chancel 4.0K 3月 5 10:19 bin
drwxrwxr-x 3 chancel chancel 4.0K 3月 5 10:19 include
drwxrwxr-x 3 chancel chancel 4.0K 3月 5 10:19 lib
lrwxrwxrwx 1 chancel chancel 3 2月 27 15:10 lib64 -> lib
-rw-rw-r-- 1 chancel chancel 91 2月 27 15:10 pyvenv.cfg
使用虚拟环境,也方便将项目依赖打印成 requirements.txt 文件
pip3 freeze > requirements.txt
日志库在每一个编程语言里都是基础设施之一,日志记录对于程序来说,包括不限于以下3点作用
logging 是 Python 的日志库
编辑代码如下
import logging
import auxiliary_module
logger = logging.getLogger('app') # 创建一个名为app的日志模块
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 日志输出格式
file_handler = logging.FileHandler('app.log') # 创建一个文件Handler对象用于控制日志输出到文件
file_handler.setLevel(logging.DEBUG) # 文件Handler对象的输出级别为Info
file_handler.setFormatter(formatter) # 设置文件Handler对象的日志输出格式
stream_handler = logging.StreamHandler() # 创建一个流输出Handler对象用于控制日志输出到控制台
stream_handler.setLevel(logging.ERROR) # 流输出Handler对象输出级别为Error
stream_handler.setFormatter(formatter) # 设置流对象Handler对象的日志输出格式
logger.setLevel(logging.INFO) # 设置默认输出等级为 info
logger.addHandler(file_handler) # 添加处理器到app日志模块
logger.addHandler(stream_handler) # 添加处理器到app日志模块
# 测试日志输出
logger.info('我创建了一个日志输出工具')
try:
a = '10'
c = a / 10
except Exception:
logger.exception('计算c的值出错')
运行此代码,会创建一个 app.log 文件,内容如下
2022-07-21 15:57:21,764 - app - INFO - 我创建了一个日志输出工具
2022-07-21 15:57:21,766 - app - ERROR - 计算c的值出错
Traceback (most recent call last):
File "/home/chancel/codes/python/hello-world/main-1.py", line 25, in <module>
c = a / 10
TypeError: unsupported operand type(s) for /: 'str' and 'int'
logging内置了几个对象如下:
正则表达式(Regular Expression),简称正则,是一种用来描述和匹配字符串模式的工具
在 Python 中使用 re 标准库来支持正则表达式的,常见用法如下
Python 采用反斜杠
\来表达转义,在书写 Python 正则表达式时,尽量使用r'string'的写法表示不进行Python字符串的转义
上述方法的代码示例如下:
import re
phone = '(020)3306-8081'
search_result = re.search(r'\d{3}', phone)
match_result = re.search(r'\(020\)', phone)
fullmatch_result = re.fullmatch(r'\(020\)\d+-\d+', phone)
sub_result = re.sub(r'\d{3}', '999', phone, 1)
split_result = re.split(r'\(|\)', phone)
re_compile = re.compile(r'\d{3}')
print('search area code %s' % search_result.group()) # search area code 020
print('match area code %s' % match_result.group()) # match area code (020)
print('fullmatch phone %s' % fullmatch_result.group()) # fullmatch phone (020)3306-8081
print('replace area code %s to %s' % (phone, sub_result)) # replace area code (020)3306-8081 to (999)3306-8081
print('split area code and phone %s' % split_result[1:3]) # split area code and phone ['020', '3306-8081']
print('compile pattern result %s' % re.sub(re_compile, '999', phone)) # compile pattern result (999)9996-999
线程是操作系统进行运算调度的最小单位,也称之为轻量级进程
在 Python 中,使用 threading 模块来支持线程创建和管理
Python中的线程会在一个单独系统级线程中执行(如 POSIX 线程 Windows 线程)
与其他编程语言不太一样的是,由于 全局GIL锁 的存在,Python 对于计算密集型的任务并不会真正并发的执行
编写代码如下
import threading
def print_numbers():
for i in range(5):
print(i)
# 创建两个线程
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_numbers)
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
其执行输出如下
0
1
2
3
4
0
1
2
3
4
在Python中,多线程一样会面临着锁的问题,以下面代码为例
from threading import Thread
count = 0
def Add():
global count
i = 0
while i < 500000:
count += 1
i += 1
t1 = Thread(target=Add)
t1.start()
t2 = Thread(target=Add)
t2.start()
# Wait t1 and t2 completed
t1.join()
t2.join()
print('Count value : %d' % count) # Count value : 804263
理论上应该输出1000000,但实际上输出结果不定,这就是 原子性操作被破坏 的体现
同样, Python 支持线程锁来处理这种情况
from threading import Thread, Lock
count = 0
lock = Lock()
def Add():
global count
i = 0
while i < 500000:
with lock:
count += 1
i += 1
t1 = Thread(target=Add)
t1.start()
t2 = Thread(target=Add)
t2.start()
# Wait t1 and t2 completed
t1.join()
t2.join()
print('Count value : %d' % count) # Count value : 1000000
协程(Coroutine)是一种轻量级的并发编程技术,用于在单线程内实现多个独立的执行流
它可以在执行过程中暂停和恢复,并且可以与其他协程进行通信和协作,实现高效的并发操作
与线程或进程不同,协程并不依赖于操作系统的线程调度器,而是由开发者显式地控制协程的启动、暂停和恢复
这使得协程可以实现更细粒度的并发控制,避免了线程切换的开销,提高了程序的性能和效率
为什么要使用协程?
在 Python 中,赋值操作符 = 是直接赋值,不是拷贝对象,而是创建目标与对象之间的绑定关系
代码如下
a = 100
b = a
print('a value: %s, id: %d\nb value: %s, id: %d' % (a, id(a), b, id(b)))
a = 200
print('a value: %s, id: %d\nb value: %s, id: %d' % (a, id(a), b, id(b)))
输出如下,可以看到当修改不可变类型 number 时,会创建一个全新对象
a value: 100, id: 140132334490208
b value: 100, id: 140132334490208
a value: 200, id: 140132334493408
b value: 100, id: 140132334490208
将上述代码中的 a 、 b 改成可变对象 dict ,id值不发生任何变化
a value: {'letter': 'xyz'}, id: 140385347304400
b value: {'letter': 'xyz'}, id: 140385347304400
a value: {'letter': 'pro'}, id: 140385347304400
b value: {'letter': 'pro'}, id: 140385347304400
结论:
要创建一个可变对象的副本,可以使用 copy.copy 来创建
不可变对象使用copy.copy时与赋值操作无异
代码如下
import copy
a = {'letter': 'a'}
b = copy.copy(a)
print('a value: %s, id: %s\nb value: %s, id: %s\nc value: %s, id: %s' %
(a, id(a), b, id(b), c, id(c)))
b['letter'] = 'b'
c['letter'] = 'c'
print('a value: %s, id: %s\nb value: %s, id: %s\nc value: %s, id: %s' %
(a, id(a), b, id(b), c, id(c)))
输出如下
a value: {'letter': 'a'}, id: 140697187191976
b value: {'letter': 'a'}, id: 140697267923560
a value: {'letter': 'a'}, id: 140697187191976
b value: {'letter': 'b'}, id: 140697267923560
使用copy创建的对象id值与赋值操作创建的对象id值不一样,是一个全新的副本,修改其中一个副本并不影响其他副本的值
copy.copy 是浅拷贝,当可变对象里包含可变对象时,浅复制只会创建一个最上层的可变对象的副本
而可变对象中的可变对象仍然是同一个对象,要创建一个可变对象的完整副本,我们需要使用深拷贝
代码如下
import copy
a = {'letter': ['a']}
b = copy.copy(a)
c = copy.deepcopy(a)
print('a value: %s, id: %s\nb value: %s, id: %s\nc value: %s, id: %s' %
(a, id(a), b, id(b), c, id(c)))
b['letter'].append('b')
c['letter'].append('c')
print('a value: %s, id: %s\nb value: %s, id: %s\nc value: %s, id: %s' %
(a, id(a), b, id(b), c, id(c)))
输出如下,可以看到ID值都一样,但浅拷贝的字典b修改自身字典中的数组时影响到了字典a中的数组,而深拷贝字典c则不会影响到字典a/b
a value: {'letter': ['a']}, id: 139933494184768
b value: {'letter': ['a']}, id: 139933574920808
c value: {'letter': ['a']}, id: 139933494314976
a value: {'letter': ['a', 'b']}, id: 139933494184768
b value: {'letter': ['a', 'b']}, id: 139933574920808
c value: {'letter': ['a', 'c']}, id: 139933494314976
在使用Python操作可变对象时候,需要注意赋值操作、浅拷贝、深拷贝之间的差异,避免带来错误
list-comprehensions (列表推导式)是Python中用来创建列表的一种技巧
例如:给定一个包含字符串的列表,要求筛选出字符串列表中所有包含z的字符串组成新的列表
循环处理
list_1 = ['zenith', 'apple', 'shutdown', 'zebra', 'list', 'zip', 'shift', 'zeal']
list_2 = []
for item in list_1:
if 'z' in item:
list_2.append(item)
print(list_2) # ['zenith', 'zebra', 'zip', 'zeal']
列表推导式处理
list_1 = ['zenith', 'apple', 'shutdown', 'zebra', 'list', 'zip', 'shift', 'zeal']
list_2 = [item for item in list_1 if 'z' in item]
print(list_2) # ['zenith', 'zebra', 'zip', 'zeal']
核心语法
newlist = [expression for item in iterable if condition == True]
列表推导式不仅可以推导列表,也可以用于创建字典,expression 允许填入任何表达式,如下
list_1 = ['zenith', 'apple', 'shutdown', 'zebra', 'list', 'zip', 'shift', 'zeal']
list_2 = {item: True for item in list_1 if 'z' in item}
print(list_2) # {'zenith': True, 'zebra': True, 'zip': True, 'zeal': True}
Iterator(迭代器)和 Generator(生成器)是 Python 中用于处理和生成可迭代对象的重要概念
迭代操作与列表相比更节省程序内存空间,在元素被获取之前不会生成
__iter__ 方法用于获取一个迭代器的方法,对于基础对象 list, tuple, dict 都可以使用__iter__来获取其迭代器,如下
list_1 = [1, 2, 3, 4]
iter_1 = iter(list_1)
print(next(iter_1)) # 1
print(next(iter_1)) # 2
print(next(iter_1)) # 3
print(next(iter_1)) # 4
print(next(iter_1)) # Traceback (most recent call last):...StopIteration
StopIteration 用于结束迭代器,如上述代码,在超出元素列表后,迭代器就不可用了
在 Python 中,任何实现了 __next__ 和 __iter__ 方法的对象,都称为 迭代器对象
代码如下
class MyIterator:
def __init__(self) -> None:
self._count = 0
def __iter__(self):
return self
def __next__(self):
self._count += 1
if self._count > 10:
raise StopIteration
return self._count
if __name__ == '__main__':
mi = MyIterator()
mi_iter = iter(mi)
while True:
print(next(mi_iter))
用 __next__ 和 __iter__ 可以为类配置迭代器的代码
Generator生成器 是一种特殊的迭代器,它可以通过函数来创建
def generator(n:int):
n += 1
yield n
if __name__ == '__main__':
number = 0
while number < 10:
number = next(generator(number))
print(number) # 1...10
生成器可以理解为延迟操作,跟Golang中的defer非常相似,在计算时才获得具体的值
上述的例子或许不太明显,结合列表推导式就可以看出其用法
def generator(n:int):
n += 1
yield n
if __name__ == '__main__':
generators = [generator(i) for i in range(10)]
for g in generators:
print(next(g)) # 1...10
代码中的 generators 在遍历之前并不会计算其中真正的值,这就是使用生成器的好处
迭代器和生成器提供了一种方便且高效的方式来处理和生成可迭代对象,帮助程序减少内存消耗,提高代码的可读性和性能
在实际编程中,经常使用迭代器和生成器来遍历和处理大型数据集、惰性地生成数据、实现流式处理等
Closure(闭包)是指在一个函数内部定义的函数,并且该内部函数可以访问外部函数的变量和作用域,即使外部函数已经执行结束
闭包在函数式编程中是一个重要的概念,它允许我们将函数作为一等公民来操作和传递
假设需要实现一个累加算法,以面向对象的实现方法如下
class Sum:
def __init__(self) -> None:
self._numbers = []
def add(self, number: int) -> int:
self._numbers.append(number)
sum = 0
for number in self._numbers:
sum += number
return sum
if __name__ == '__main__':
s = Sum()
print(s.add(1)) # 1
print(s.add(5)) # 6
print(s.add(10)) # 16
sum 类的 numbers 成员是希望对外界隐藏的,将数据封装在类中不被访问是常见的手段
在函数式编程中,借助闭包也可以实现类似于私有成员的效果
def add():
numbers = []
def func(number: int = 0):
numbers.append(number)
sum = 0
for number in numbers:
sum += number
return sum
return func
if __name__ == '__main__':
s = add()
print(s(1)) # 1
print(s(5)) # 6
print(s(10)) # 16
这段代码中,嵌套函数引用并访问了封闭函数的变量 numbers ,即使在外部函数已经执行结束了,此时 numbers 相当于 Free Variable(自由变量)
闭包在编程中有多种应用,例如:
Decorator(装饰器)是一种在 Python 中用于修改、扩展或包装函数或类的技术
Python支持函数式编程,函数被视为一等公民(First-class citizen),特点如下:
在Python中,任何实现了__call__方法的对象都是可调用函数
Python中的Object是对数据的抽象
在Python中,装饰器是也一种函数,本质上是接受一个函数,添加一些额外的功能,然后返回给调用者
def sum(x, y):
return x+y
def verify(func):
def _(*args):
for arg in args:
if type(arg) != int:
return -1
return func(*args)
return _
if __name__ == '__main__':
s = verify(sum)
print(s(10, 100)) # 110
print(s(10, 'a')) # -1
函数 verify 是一个装饰器,可以为 sum 方法的调用进行参数检查
每次调用sum都需要显式调用 verify 是比较麻烦的,Python提供 @ 进行函数装饰
标准装饰器写法如下
def verify(func):
def _(*args):
for arg in args:
if type(arg) != int:
return -1
return func(*args)
return _
@verify
def sum(x, y):
return x+y
if __name__ == '__main__':
print(sum(10, 100)) # 110
print(sum(10, 'a')) # -1
使用 @ 对函数进行装饰,以较低的代码入侵实现对函数的功能修改
Global Interpreter Lock 是采用CPython解释器的Python版本拥有的特性,用于防止多线程并发执行机器码
GIL 确保在任何时候,只有一个线程可以执行Python字节码,这主要是为了简化内存管理
但即使有GIL,不同线程也可以在GIL释放的情况下被调度并切换,这可能导致竞态条件
竞态条件(Race Condition)是指在多线程或并发编程中,当多个线程同时访问和修改共享的资源时,最终的结果依赖于线程执行的具体时序,而导致无法得到确定性的正确结果
对于 GIL ,Python开发时要注意:
代码如下
import time
from threading import Thread
def Add(n: int):
count = 1
for i in range(2, n):
count = count + i
print('Count: %s' % count)
start = time.time()
Add(100000000) # Count: 4999999950000000
Add(100000000) # Count: 4999999950000000
print('Run time: %0.3f\n' % (time.time() - start)) # Run time: 15.024
start = time.time()
t1 = Thread(target=Add, args=(100000000, )) # Count: 4999999950000000
t1.start()
t2 = Thread(target=Add, args=(100000000, )) # Count: 4999999950000000
t2.start()
# Wait t1 and t2 completed
t1.join()
t2.join()
print('Run time of thread: %0.3f' % (time.time() - start)) 3 Run time of thread: 15.406
对于计算100000000以内的累加算法,双线程的速度甚至慢于单线程的
...
requests 是 Python 中一个强大的同步请求网络工具库
pip安装如下
pip3 install requests
GET 请求示例
import requests
r = requests.get('https://api.chancel.me/rest/api/v1/ip')
print(r.status_code) # 200
print(r.json()) # {'status': 1, 'msg': 'Query success', 'data': {'ip': '14.145.139.148'}}
POST 请求示例
import requests
r = requests.post('https://api.chancel.me/rest/api/v1/telegram')
print(r.status_code) # 200
print(r.json()) # {'status': 0, 'msg': 'Not Found', 'data': None}
在发起模拟请求时,通常需要在HTTP的 Headers 中添加自定义头
如下代码,在POST请求的 Headers 中添加一个TOKEN令牌
import requests
headers = {
'TOKEN': 'JUST DO IT'
}
r = requests.post('https://api.chancel.me/rest/api/v1/telegram',headers=headers)
print(r.status_code) # 200
print(r.json()) # {'status': 0, 'msg': 'Not Found', 'data': None}
requests 对于 cookies 的修改一样方便
import requests
data = {'id': 91}
cookies = {'IDTAG': '17ab96bd8ffbe8ca58a78657a918558'}
r = requests.post('https://www.chancel.me/manage/favorites', json=data, cookies=cookies)
print(r.status_code) # 200
print(r.json()) # {'status': 0, 'msg': 'Not Login!', 'data': None}
Json Post请求
import requests
url = 'https://jsonplaceholder.typicode.com/posts'
data = {
'title': 'foo',
'body': 'bar',
'userId': 1
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(url, json=data, headers=headers)
print(f'Status Code: {response.status_code}')
print(f'Response Body: {response.json()}')
表单 Post请求
import requests
url = 'https://jsonplaceholder.typicode.com/posts'
data = {
'title': 'foo',
'body': 'bar',
'userId': 1
}
response = requests.post(url, data=data)
print(f'Status Code: {response.status_code}')
print(f'Response Body: {response.json()}')
两者的区别在于数据的编码方式和 Content-Type 头的设置,具体使用哪种方式取决于服务器的要求
有些请求过程是连续的,包括302重定向、Cookies设置等操作,可以借助 requests.session 来实现
代码如下
import requests
# 以下2次请求Cookies值均发生了变化,说明服务端认为这是2次全新的请求
r = requests.get('https://www.chancel.me')
print(r.cookies) # <RequestsCookieJar[<Cookie IDTAG=b6db65da-01bc-11ed-94db-00163ec8adc0 for www.chancel.me/>]>
r = requests.get('https://www.chancel.me')
print(r.cookies) # <RequestsCookieJar[<Cookie IDTAG=c0e7b190-01bc-11ed-8c4c-00163ec8adc0 for www.chancel.me/>]>
# 以下2次请求的Cookies值不变,对服务端来说相当于是同一个用户请求2次
s = requests.session()
r = s.get('https://www.chancel.me')
print(s.cookies) # <RequestsCookieJar[<Cookie IDTAG=0c36c265-01bd-11ed-b6ac-00163ec8adc0 for www.chancel.me/>]>
r = s.get('https://www.chancel.me')
print(s.cookies) # <RequestsCookieJar[<Cookie IDTAG=0c36c265-01bd-11ed-b6ac-00163ec8adc0 for www.chancel.me/>]>
diskcache 是一个 Python 库,用于提供一个基于磁盘的缓存系统
它可以用于存储和检索 Python 对象,以减少重复计算或重复获取数据的开销
使用 pip 安装如下
pip install diskcache
使用非常简单,示例如下
from diskcache import Cache
class Man:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
cache = Cache('cache')
cache.set('admin', Man(name='chancel', age=80)) # or add() but key must not already
user = cache.get('admin')
print('admin name is %s, age is %d' % (user.name, user.age)) # admin name is chancel, age is 80
使用 diskcache 可以快速的将对象数据写入本地磁盘,在下次启动时读取数据
设置数据时候可以携带参数 expire 限制数据的有效期,单位是秒,代码如下
import time
from diskcache import Cache
class Man:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
cache = Cache('cache')
cache.set('admin', Man(name='chancel', age=80),expire=3)
user = cache.get('admin')
print('admin name is %s, age is %d' % (user.name, user.age)) # admin name is chancel, age is 80
time.sleep(5)
user = cache.get('admin')
print('admin name is %s, age is %d' % (user.name, user.age)) # exception 'NoneType' object has no attribute 'name'
PyInstaller 是一个用于将 Python 程序打包成独立可执行文件的工具
为了方便说明,假设文件目录如下
├── requirements.txt
└── src
├── main.py
└── utils.py
使用 pip 安装如下
pip3 install pyinstaller
如果你的Python环境是使用 pyenv 进行管理的,可能需要在安装上添加共享库打包选项
否则在使用 pyinstaller 打包时,可能会遇到so错误提示
pyenv 安装 Python 时添加共享库命令如下
env PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install 3.7.2
程序入口是 main.py 文件,其中引用了 utils.py 模块,打包方法如下:
pyinstaller -F src/main.py
-F参数表示打包压缩成一个文件,与之对应的是默参-D,表示打包程序,打包后目录如下
├── build
│ └── main
│ ├── Analysis-00.toc
│ ├── base_library.zip
│ ├── EXE-00.toc
│ ├── main.pkg
│ ├── PKG-00.toc
│ ├── PYZ-00.pyz
│ ├── PYZ-00.toc
│ ├── warn-main.txt
│ └── xref-main.html
├── dist
│ └── main.exe
├── main.spec
├── requirements.txt
├── logging.yaml
└── src
└── main.py
在 dist 目录下可以看到一个 main.exe 二进制文件,这就是打包后的二进制文件,该二进制文件在不安装任何Python环境下直接运行
如果不使用 -F 参数,则可以额外看到一个 dist/main/ 文件夹,里面存放了一些 .dll 和 .so 文件用来支持exe运行
-F参数本质上只是打包 .dll 和 .so 文件到exe中,在运行时释放出来
main.spec 是打包的配置文件,通过修改它可以实现各种复杂的打包效果
使用 main.spec 进行打包
pyinstaller ./main.spec
main.spec 的配置参考手册:
程序运行时,经常会需要配置文件,如 config.yaml
编写测试代码如下
from yaml import safe_load
with open('config.yaml', 'r', encoding='utf-8') as f:
config = safe_load(f)
print(config)
在执行这段代码时,项目目录下需要有 config.yaml 文件
想要实现将 config.yaml 文件也打包到exe中,代码方面改动如下
from yaml import safe_load
import sys, os
def get_resource(relative_path: str):
if getattr(sys, 'frozen', False):
base_path = sys._MEIPASS
else:
base_path = os.path.abspath(".")
return os.path.join(base_path, relative_path)
with open('config.yaml', 'r', encoding='utf-8') as f:
config = safe_load(f)
print(config)
在上面的代码中,添加了 get_resource 方法来获取资源文件
然后修改打包配置文件 main.spec ,将 config.yaml 文件一并打包到exe中
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(['src/main.py'],
pathex=['config.yaml'],
binaries=[],
datas=[('config.yaml','.')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='main.exe',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True,
disable_windowed_traceback=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None )
这样,打包出来的exe中就含有资源文件 config.yaml 了
分发二进制文件,通常需要防止反编译,常见的三种方式:
pyc 文件,防止程度无在 pytinstaller 中,修改 main.spec 的 block_cipher 参数添加aes密钥即可
# -*- mode: python ; coding: utf-8 -*-
block_cipher = pyi_crypto.PyiBlockCipher(key='18sh@t73bkasd932')
a = Analysis(['src/main.py'],
pathex=['logging.yaml'],
binaries=[],
datas=[('logging.yaml','.')],
hiddenimports=[],
hookspath=[],
...
此时可以试试解压exe再反编译pyc文件查看代码内容是否已经被加密
Retrying 是一个以Apache 2.0许可证发布的通用重试库,用Python编写,旨在简化为任何事物添加重试行为的任务
安装如下
pip install retrying
以下是一个使用 retrying 中 retry 模块的简单示例:
from retrying import retry
# 定义一个需要重试的函数
@retry
def fetch_data(url):
# 假设这里是一个可能出现网络错误的操作
response = requests.get(url)
return response.text
# 调用函数,并自动进行重试
data = fetch_data("https://example.com")
print(data)
在上述示例中,fetch_data 函数使用了 @retry 装饰器,当 requests.get(url) 发生网络错误时,retry 模块将自动重试该操作,直到达到默认的最大重试次数(默认为3次)
通过使用 retry 模块可以更方便地处理可能出现错误的函数,并在需要时进行灵活的重试操作,以增加程序的稳定性和容错性,同时也提供了十分丰富的错误重试设定
@retry(stop_max_attempt_number=5) # 设置重试次数为5次
def fetch_data(url):
...
@retry(wait_fixed=2000) # 2秒后进行下一次重试
def fetch_data(url):
...
@retry(stop_max_attempt_number=3, retry_on_result=lambda result: result is None) # 设定负责的重试条件
def fetch_data(url):
...
@retry(stop_max_attempt_number=3, retry_on_exception=IOError) # 捕获特定的异常进行重试
def fetch_data(url):
...
这只是 retrying 模块的一小部分用法示例,还有更多选项和配置可以根据具体需求进行使用,更多用法可以参考官方文档