
Chancel's blog
有善始者实繁,能克终者盖寡。
作者:Chancel Yang, 创建:2019-03-01, 字数:3313, 已阅:5, 最后更新:2024-06-14
ChatGPT非常惊艳,网上也有不少教程科普其原理,还有导入聊天记录训练定义数字化的自己之类的教程,非常有意思,这篇文章将记录实践部署一个类ChatGPT的对话机器人,实测有70%左右ChatGPT水平。
在开始之前,先了解一下现在比较流行的几个常见语言模型
本文基于Vicuna-13b作为说明,搭配FastChat搭建部署一个对话聊天机器人,该模型运行要求配置不低于以下标准
如果配置达不到要求,可以考虑下Vicuna-7b模型等对配置需求低一些的模型
我的系统是Ubuntu2204,实测Windows11也可以完美运行,操作系统请自行选择
首先克隆FastChat仓库,并进入仓库
git clone https://github.com/lm-sys/FastChat
cd FastChat
这里我安装了python3.10.10,确保Python版本高于3.7即可
创建虚拟环境并激活(可选)
python3.10.10 -m venv venv
source venv/bin/active
安装依赖
pip3 install --upgrade pip
pip3 install -e .
FastChat在Vicuna-13b基础模型的基础上添加了部分权重,这部分过程需要我们手动添加
也可以在网上找到已添加的模型文件
Vicuna-13b的模型我选择了lmsys的vicuna-13b-delta-v1.1,以下是仓库地址
首先创建存放模型的文件夹,再将仓库克隆到本地,注意这个仓库非常大,需要魔法网络确保下载速度
mkdir models && cd models
git lfs install
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
按照FastChat仓库的要求,给Vicuna-13b添加自定义权重,以下转化要求配置不低于60Gb的RAM
python3 -m fastchat.model.apply_delta \
--base-model-path models/vicuna-13b-delta-v1.1 \
--target-model-path models/vicuna-13b-delta-v1.1-output \
--delta-path lmsys/vicuna-13b-delta-v1.1
这个过程视网络情况而定,通常需要1个小时左右
等待模型合并完成之后,就可以运行测试,以下命令要求显卡不低于28Gb显存
python3 -m fastchat.serve.cli --model-path models/vicuna-13b-delta-v1.1-output
运行此命令后会得到一个CLI对话界面,此时可以正常测试对话效果
或者运行网页端查看效果
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path models/vicuna-13b-delta-v1.1-output
python3 -m fastchat.serve.gradio_web_server
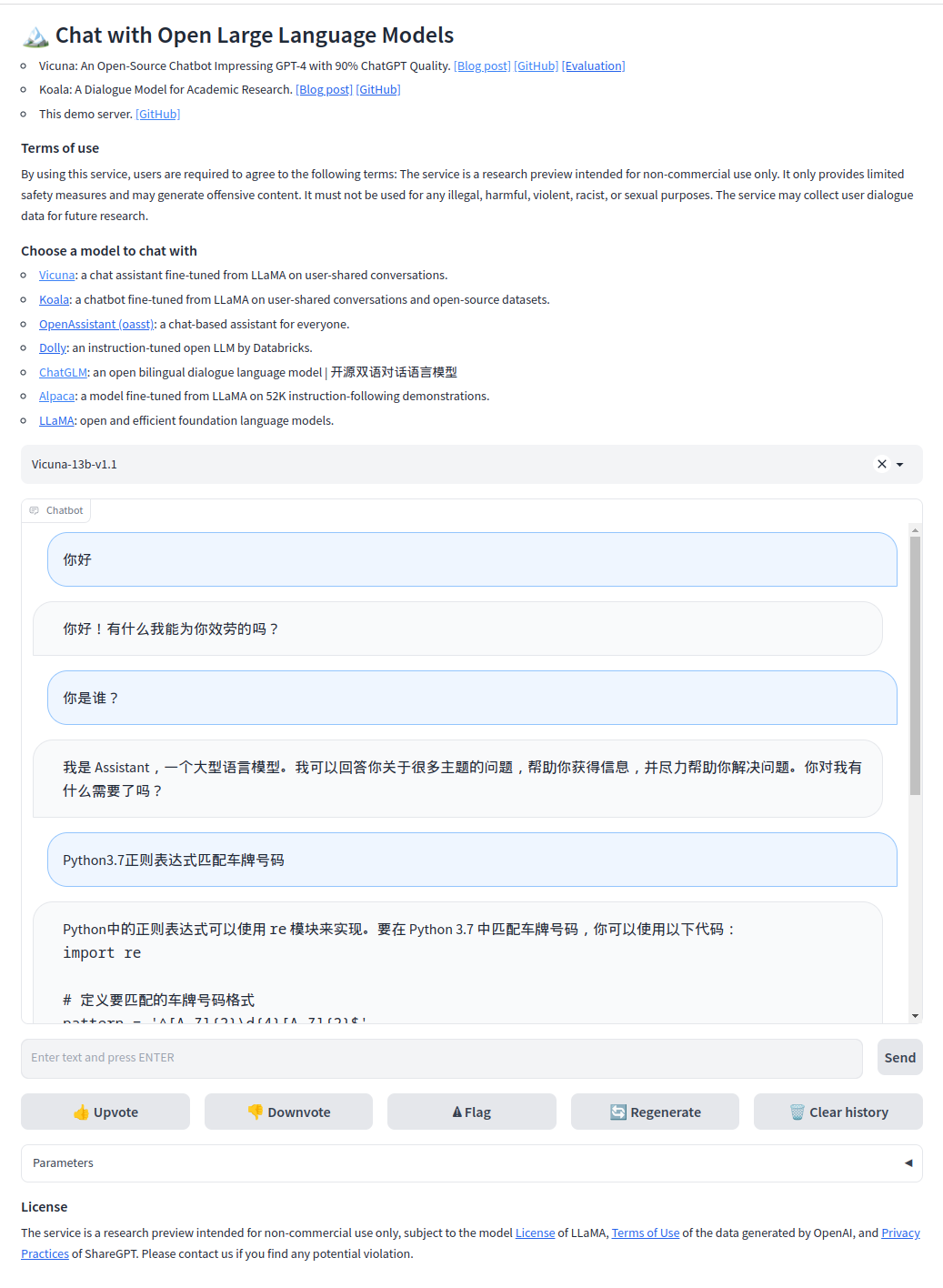
访问 http://127.0.0.1:7860 可以看到如下效果
在Ubuntu2204下安装CUDA,可以参考Nvidia官方文档
下面简述一下步骤
检查nvidia硬件情况,确保硬件安装没有问题
lspci | grep -i nvidia
确保gcc已安装
gcc --version
然后访问 developer.nvidia.com ,并根据情况选择操作系统,之后页面会给出安装命令,例如
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
验证安装结果
sudo nvidia-smi
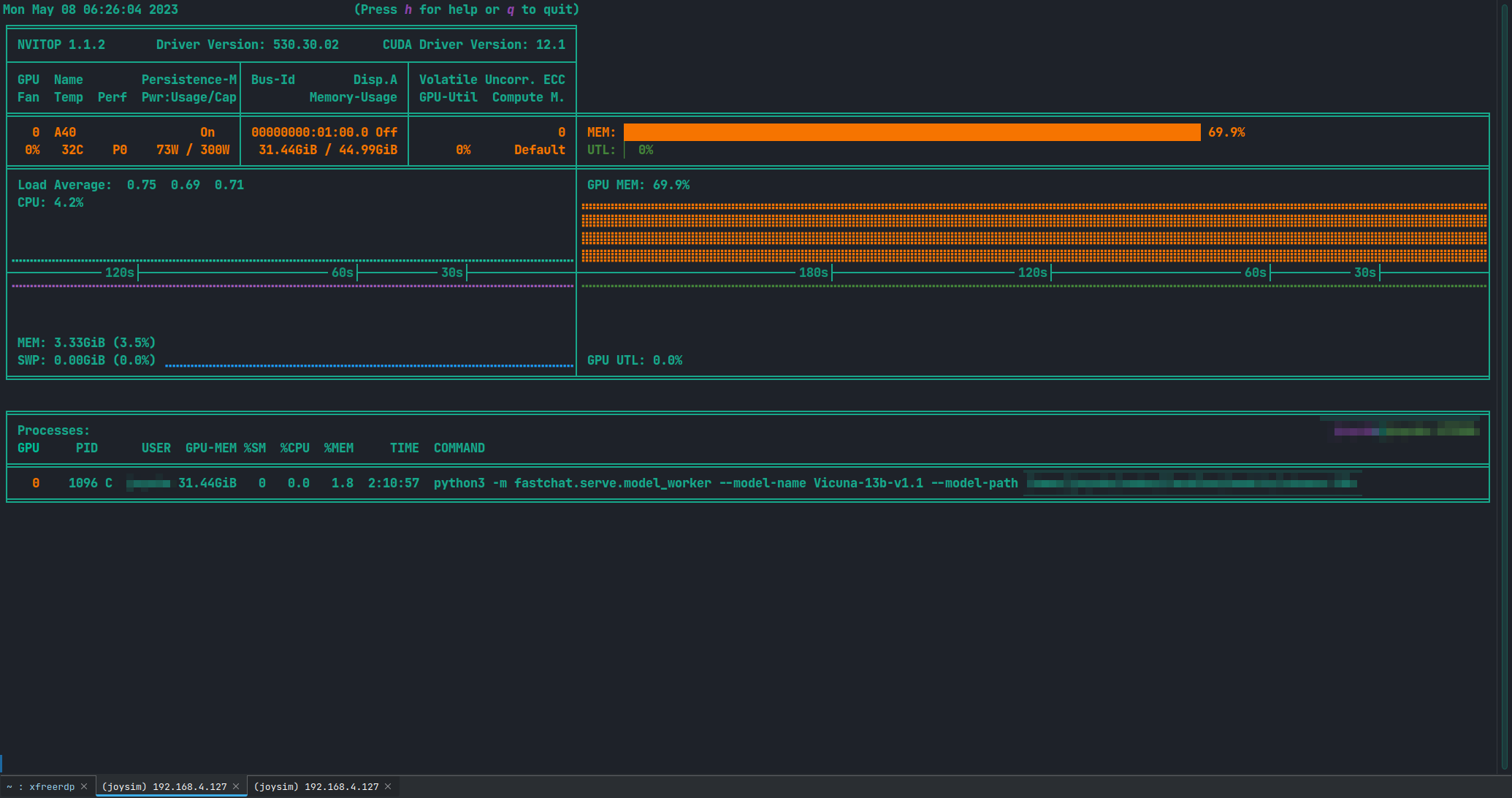
运行模型对显卡负担比较大,所以有必要实时监控显卡状态,Nvidia显卡可以参考下面这个仓库进行监控
使用方法非常简单,可以在上述的Vicuna-13b虚拟环境中安装nvitop
pip3 install --upgrade nvitop
直接运行后,效果如下
资料参考