
E4b9a6's blog
有善始者实繁,能克终者盖寡。
作者:E4b9a6, 创建:2024-03-07, 字数:3688, 已阅:4615, 最后更新:2024-03-07
这篇文章更新于 413 天前,文中部分信息可能失效,请自行甄别无效内容。
ollama是一款用于本地运行大语言模型的工具,原来运行大语言模型步骤如下:
nvidia相关的驱动和docker环境huggingface.co拉取合适的仓库相较于这些繁琐且需要具备一定运维基础的操作,ollama提供了一种开箱即用的方法:
nvidia相关的驱动和docker环境ollama的docker容器,并指定具体模型名称即可与之在web端畅聊ollama将自动帮助你完成安装模型、运行模型、调整参数乃至于搭配对应的web端,一步实现与大语言模型聊天
下面将实践如何安装使用ollama
服务器的配置如下
以下操作均基于以上配置进行
在Ubuntu2204下安装CUDA,可以参考Nvidia官方文档
首先检查nvidia硬件情况,确保硬件正常接入系统
lspci | grep -i nvidia
确保gcc已安装
gcc --version
然后访问 developer.nvidia.com ,并根据情况选择操作系统,之后页面会给出安装命令,ubuntu2204安装方法如下:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.1-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
最后验证安装结果
sudo nvidia-smi
如正常输出显卡驱动版本号即没有问题
此次运行需要docker以及docker-compose,在Ubuntu2204上安装如下
sudo apt update
sudo apt install docker.io docker-compose
sudo systemctl start docker
sudo systemctl enable docker
如果所在服务器是国内,在拉取镜像的时候会特别慢,此时可以借助科学代理来加速拉取网站
export http_proxy=http://localhost:8080
export https_proxy=http://localhost:8080
sudo docker pull hello-world
ollama官网:ollama.com
此次运行是包括web端的一起运行,所以使用docker-compose打包一起运行以下容器:
首先克隆仓库:https://github.com/open-webui/open-webui.git
克隆后进入仓库目录,并修改docker-compose.yml文件,修改如下:
version: '3.8'
services:
ollama:
...
# gpu运行需增加runtime和environment
runtime: nvidia
environment:
NVIDIA_VISIBLE_DEVICES: all
...
open-webui:
...
volumes:
...
此处会遇到一个问题,容器运行后访问 http://localhost:18080 ,登录后会白屏3分钟才加载成功,非常影响用户体验
猜测是网络加载问题,经过排查发现是该容器默认会请求 api.openai.com 以获取模型列表
由于服务器是在国内,国内的网络访问openai是众所周知的问题,所以访问超时之后,才会显示聊天界面
如果你的网络访问 openai 的服务也会有问题,请在docker-compose.yml加入如下修改:
version: '3.8'
services:
ollama:
...
open-webui:
...
environment:
...
# 加入自定义可以访问的 openai 地址取代原有的open api地址
- 'OPENAI_API_BASE_URL=https://[your_agent_domain]/v1'
...
volumes:
...
修改docker-compose.yml文件结束后,尝试启动容器
sudo docker-compose up
稍微等待几分钟,当日志中出现open-webui加载成功后就可以访问,界面应如下:
在等待期间,我们可以进入ollama容器中,拉取需要的大模型,目前官网支持的大模型列表:
更多模型可以参考官方手册:https://ollama.com/library
进入容器方法如下
sudo docker exec -it [your_container_id] /bin/bash
拉取指定的大语言模型
ollama pull gemma:7b
拉取后无需重启,只需刷新网页即可看到大语言模型的选项
第一次需要注册,第一个注册的用户即是管理员,注册后登入主系统就可以开始聊天了,测试如下
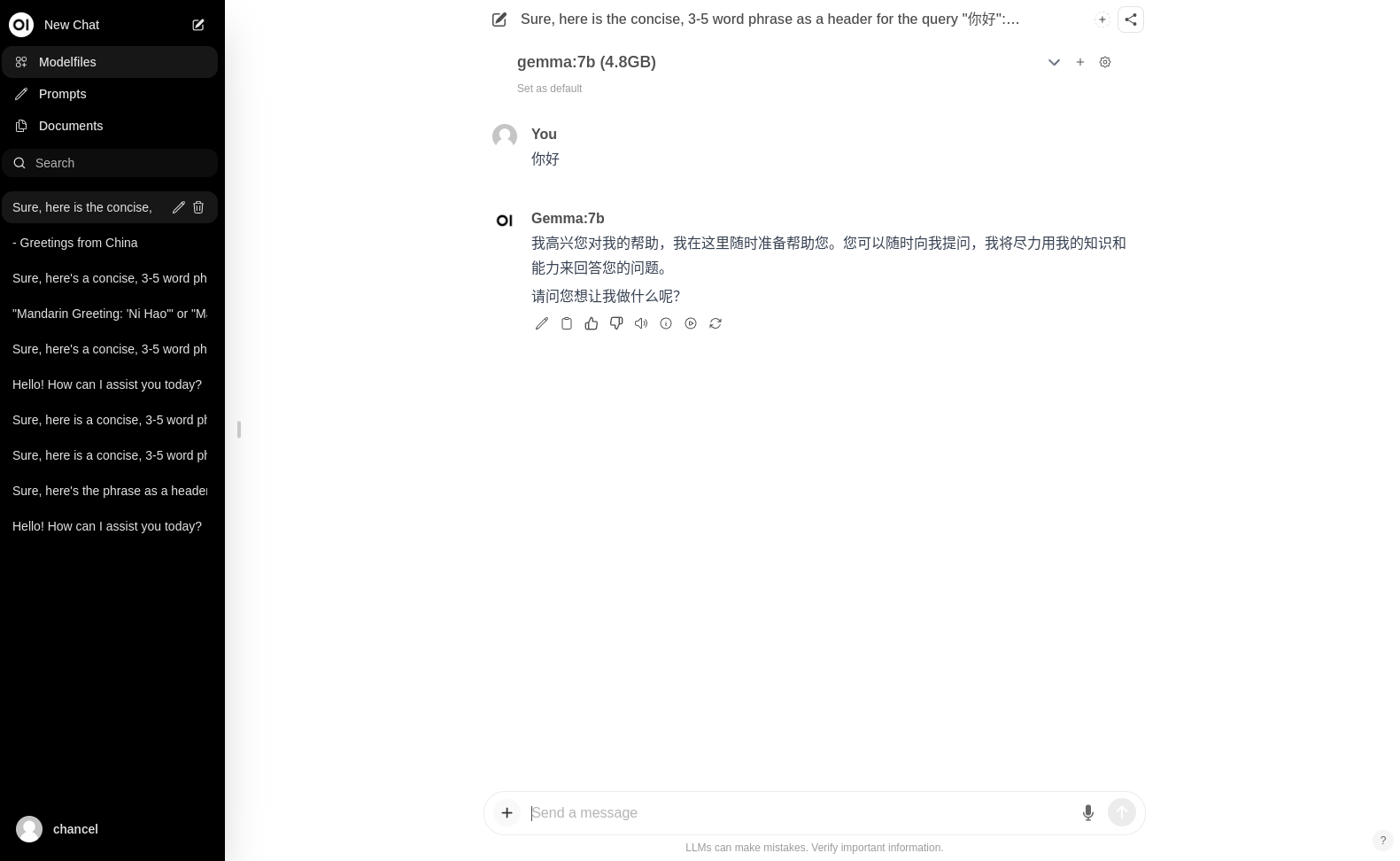
ollama很好的降低了大语言模型的部署难度,以较低的时间成本试验各大语言模型,目前的缺点是支持的大语言模型算不上丰富,期待后续更新
参考文献